Category: Machine intelligence
-

Algorithm Arrogance at Facebook
Facebook tweaks its timeline algorithm. Is this Algorithm Arrogance? Probably.
-
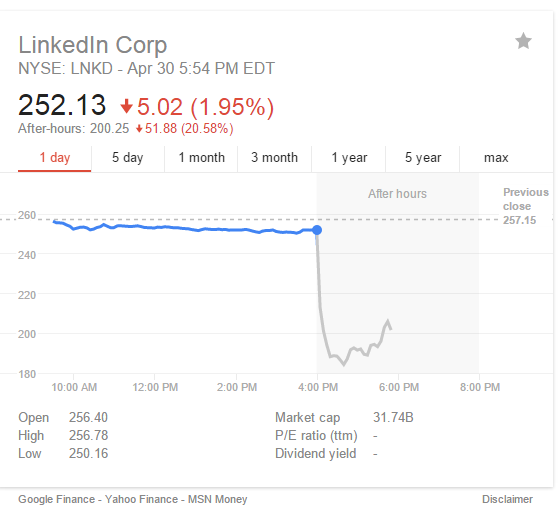
Chasing Big Data Variety: Predictive Analytics, Meet Your Market Foe
The graphic shows the market behavior of LinkedIn’s stock price late afternoon of 2015-04-30. Did your analytics engine (What’s an analytics engine? See International Institute for Analytics) predict this? If not, what (big?) data were you missing? If not, chances are, yours was a Big Data Variety problem. Correlating with, for example, only Facebook,…
-

Why Computers (and Doctors) Need Narratology
The analysis by Peter Kramer @PeterDKramer in the New York Times story “Why Doctors Need Stories” points, in part, to the challenge faced by clinical decision support systems (CDSS) — and the use of artificial intelligence in health care more generally. While CDSS adoption lags far behind its apparent value, it is true that CDSS is weak…
-

Celebrity’s Anonymous Pen Name ‘Outted’ by Software
The role that software plays in stylistic analysis of text is perhaps less surprising to high school and college students than to the general public. The former must submit essays they write to style analysis performed by software which looks for plagiarism and sometimes also makes quality assessments. In the recent outing of J.K. Rowling…
-

Will $100M Trickle Watson Down to SMB Enterprises?
Bloomberg News reported that IBM plans to invest an additional $100 million in its Watson technology. Earlier in 2011, Watson exceeded previously unmet expectations for artificial intelligence by easily overwhelming two Jeopardy!champions on national TV. While Watson-like technologies could be used in a variety of settings (e.g., network management or health care), the steep investments IBM has already made suggest…