



There was plenty of hand-wringing when Google announced that it was ceasing support for Google Reader. As is somewhat typical with Google’s project kills, it was a relatively precipitous decision that had analysts scratching their heads and users scurrying for alternatives.
Feedspot is one of several browser-based Really Simple Syndication (RSS) readers that offers features similar to Google Reader, and — this was critical for many users — includes Outline Processor Markup Language (OPML) import. OPML was the format used to export RSS feeds from Google Reader, as well as for other applications, including the venerable Microsoft Outlook.
As one of the refugees from Google Reader, I had many feeds spanning several engagements since 2005, I had a modest set of hierarchically structured feeds. Some of the folders were quite deep — e.g., “MusicTech” had 77 feeds, while others had just a few. I was a fairly energetic user of folders for structuring as well, and it is easy to imagine that others had more extensive lists. In total, there were around 750 RSS feeds. These were successfully imported into Feedspot in around 20 minutes in the middle of the day EST (US).
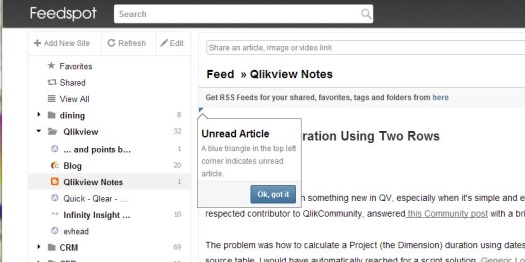
Feedspot has the feel of a relatively mature application. The small touches are part of this impression, such as the “tooltips.” An example is shown in the screenshot: “Unread article: A blue triangle in the top left corner indicates unread article. . .” Other examples include the list-view toggle and the rightmost “Feedback” button leading to a UserVoice dialog. Feedspot also allows building of RSS collections — essentially, feeds of feeds, at the level of folders.
A so-called “modern” application must integrate numerous sharing opportunities, and Feedspot follows this trend. Features for sharing content are provided in several spots [sic]. Following of user collections is possible (“follow all of my stuff”) and the obvious — sharing of individual articles.
There are still some rough edges here and there. It was unclear how to place a new manually entered feed, place it into a folder, or how to create more than a 2 level hierarchy if that is supported.
RSS content is sufficiently important that I have placed my post-Reader bets on more than one pony. Feedspot is one of them. It deserves serious consideration as a Google Reader replacement.
Founder on the Spot
I corresponded with FeedSpot founder Agarwal about the Company. He disclosed that FeedSpot was built using agile methods, and that it runs on a LAMP stack. His business goal? He says he always wanted to build “a consumer internet product.” Why RSS? Because, he wrote, “for some users an RSS reader is a must-have product.” But Agarwal believes it is possible to “take an RSS reader to mainstream consumers.”
Future of RSS?
The cancellation of Google Reader had some pundits predicting the end of RSS. Some consider the Facebook-dominated landscape as superceding the lowly RSS. The RSS button, they say, is losing ground to “Follow” and “Like” buttons. Indeed, there is a rich future ahead for the underlying data from those interactions. Still, it safe to say that pronouncements of the death of RSS are premature. RSS is widely used in content management systems (e.g., Blogger, WordPress, Sharepoint and Joomla) to import links to relevant articles. This is true for externally produced content, of course, but perhaps it has even greater value as a rapid information aggregator for smaller scale intranets whose limited staffing prevents more sophisticated schemes.
RSS, partly because of its UserLand roots, offers a simple but flexible framework for information management. It doesn’t deliver a directly usable ontology from an automation standpoint, but its wide adoption gives users great leverage to employ ad hoc schemes.
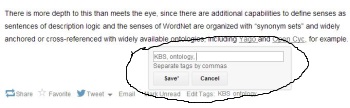
The addition of tagging features in Feedspot strengthens the quasi-ontology capability in RSS. If judiciously used with a controlled vocabulary, search can be more fruitful. As longtime users of Gmail can attest, having to choose between folders and tagging was an uncomfortable either/or decision. Eventually Gmail would offer both for classifying email. Having this capability for managing RSS is helpful.
There is more fertile ground in the reference community, such as RSS feeds that are supported in ResearchGate, CiteULike and academic publishers. If feed schemas become more sophisticated, feed users could deploy them more rapidly. Content publishing based on feeds would more often reach appropriate reader communities. Content delivery at present is notoriously hit-and-miss, especially since bloggers can readily veer off the ostensible topic of the blog.
These are growing pains that have made the semantic web grow so unsteadily. But Feedspot and like tools are perfectly good hammers for the right kind of nail.
[schema type=”review” url=”http://knowlengr.com/blog-type/feedspot-rss-reader-for-google-reader-diaspora/” name=”Feedspot: RSS Reader for Google Reader Diaspora” description=”Blog site fror Krypton Brothers founder Mark Underwood. He blogs under the name “knowlengr” (knowledge engineer).” rev_name=”Feedspot” rev_body=”A review of the RSS reader Feedspot” author=”Mark Underwood (“knowlengr”)” pubdate=”2013-07-27″ ]